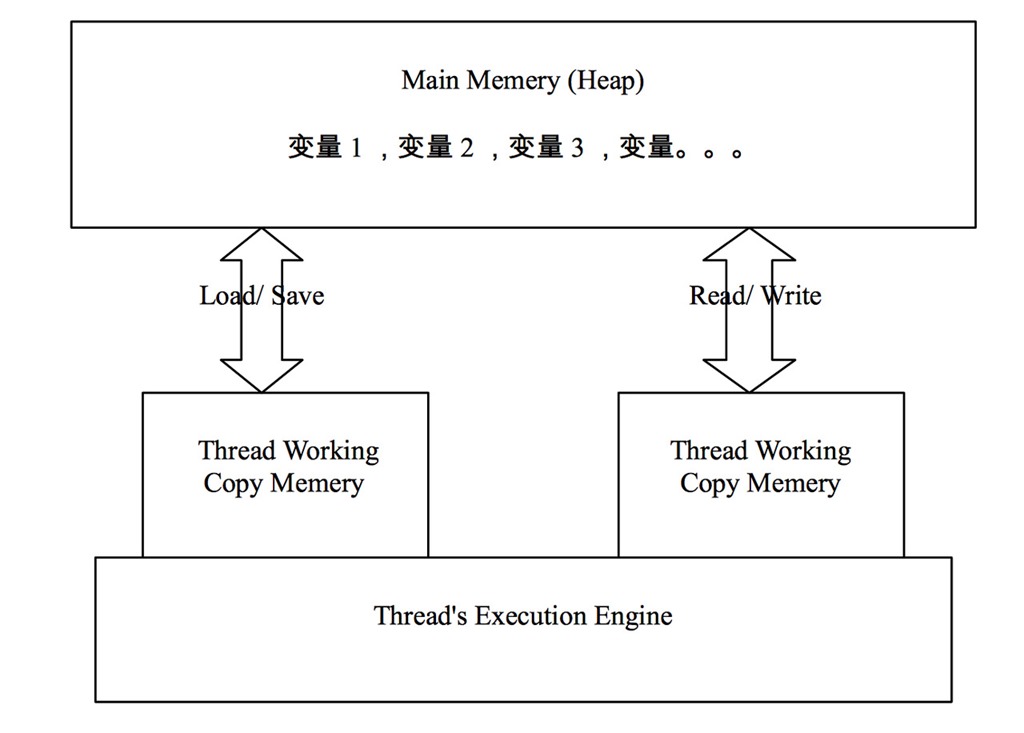
最近在学习Java高并发秒杀API,项目使用SpringMVC、Spring和MyBatis框架来实现,其中必然要学习Spring与MyBatis的整合。
在spring整合mybatis单元测试中碰到如下问题:
org.springframework.beans.factory.BeanCreationException:
Error creating bean with name 'sqlSessionFactory' defined in class path resource [spring/spring-dao.xml]:
Cannot resolve reference to bean 'classpath...