这里主要针对Hadoop1中Mapreduce的性能调优,Hadoop2的MapReduce的性能调优大同小异。
这里主要涉及的参数包括:
HDFS:
dfs.block.size
Mapredure:
io.sort.mb
io.sort.spill.percent
mapred.local.dir
mapred.map.tasks & mapred.tasktracker.map.tasks.maximum
mapred.reduce.tasks & mapred.tasktracker.reduce.tasks.maximum
mapred.reduce.max.attempts
mapred.reduce.parallel.copies
map...
HDFS block自动进入安全模式(safe mode)原因及解决方案
实验中碰到了如下问题:
问题描述:
The number of live datanodes 3 has reached the minimum number 0.
Safe mode will be turned off automatically once the thresholds have been reached。
可能原因: 因磁盘空间不足,内存不足,系统掉电等其他原因导致dataNode datablock丢失。
一般来说,这是由于系统断电,内存不足等原因导致dataNode丢失超过设置的丢失百分比,系统自动进入安全模式。
下面我将...
从零学习Hadoop之HDFS的Federation机制

上一篇介绍了Hadoop2中的新特性HA机制,是由于单节点故障而开发的,并且提到随着集群规模的变大,NameNode成为性能的瓶颈,而这次介绍一下HDFS的Federation机制就是为了解决这两个问题而开发的。
在Hadoop1的HDFS架构中,HDFS集群只有一个名字空间,并且只有单独的一个NameNode,这个NameNode负责对这单独的一个名字空间进行管理。这也正是单点失效(Single Point Failure)的隐患所在。
可得:HDFS Federa...
从零学习Hadoop之HDFS的HA机制

Hadoop2.0.0版本之前,NameNode是HDFS集群的单点故障点,每一个集群只有一个NameNode,如果这个机器或者进程不可用,整个集群则无法使用,直到重启NameNode或者新启动一个NameNode节点。
那么,导致HDFS集群不可用的两种主要情况:
类似机器宕机,Hadoop1解决方式:重启NameNode。
计划内的软件或者硬件升级(NameNode节点),将导致集群在段时间范围内不可用。
HDFS的高可用性(High Availablity)就可...
从零学习Hadoop之文件在HDFS中的读取和写入
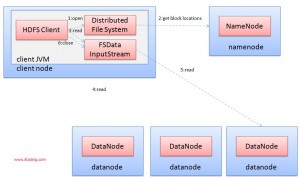
在《从零学习Hadoop之Hadoop的RPC机制》中介绍了Hadoop的RPC机制,本文接着讲述文件是如何在HDFS中进行读取和写入的,注意其中使用到RPC的地方。
文件的读取
客户端以及与之交互的HDFS、NameNode、DataNode的读取数据流如下图所示:
文件读取的过程如下:
使用HDFS提供的客户端开发库Client,向远程的NameNode发起RPC请求。
NameNode会视情况返回文件的部分或者全部Block列表,对于每个Blo...
从零学习Hadoop之认识HDFS

Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是一个用在普通硬件设备上的分布式文件系统。它与现有的分布式文件系统有很多近似的地方,但是又和这些文件系统有许多不同的地方。
HDFS
HDFS开始是为开源的Apache Nutch项目的基础结构而创建,HDFS是Hadoop项目的一部分,而Hadoop又是Lucene的一部分。
HDFS的特点
高容错性,可以用来部署在低廉的硬件上。
高吞吐量,用来访问应用程序的数...
从零开始搭建Hadoop-0.20.2平台的详细过程

说在前面的话
本来是之前写在我的另外一篇博客cndwzone.com的文章,时间是2014年6月份的,现在借用一下,由于当时对搭建Hadoop-0.20.2版本记录的比较详细,当然回过头看看,还是存在一些问题,比如SSH是为什么了什么,里面的密钥起到什么作用,当时没有深究,可能会对原理性的东西进行学习记录。
由于硬件限制,我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,不...
大数据生态技术圈介绍
知乎所见,Xiaoyu Ma对Hadoop生态系统的回答真是简直了,非常赞。下面是对他回答的引用。
大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的。你可以把它比作一个厨房所以需要的各种工具。锅碗瓢盆,各有各的用处,互相之间又有重合。你可以用汤锅直接当碗吃饭喝汤,你可以用小刀或者刨子去皮。但是每个工具有自己的特性,虽然奇怪的组合也能工...
初识Hadoop从零学习
《Hadoop权威指南》第一章中,有一段对Hadoop非常形象的介绍,介绍如下:
在古时候,人们用牛来来拉重物。当一头牛拉不动一根圆木时,人们从来没有考虑过要培育更强壮的牛。同理,我们也不该想方设法打造超级计算机,而应该千方百计综合利用更多计算机来解决问题。
-格雷斯·霍珀(Grace Ho...
学习Hadoop-说在前面的话
关于Hadoop,大学期间对这个词汇都是闻所未闻,更别说是做什么的了,最初最初接触到这个词是考研复试前,大海跟我提到google的MapReduce,根本无法想象这是什么。无独有偶选得导师在复试后让我回去学习一下Hadoop和Yarn,带着好奇和疑问买了《Hadoop权威指南》,书到手,感觉是完全是天书啊,完全看不懂啊。只有慢慢啃和从网上查相关资料,完全是盲人摸象,既然如此就一边实践一边了解。于是就搭建Hadoop伪...