从零学习Hadoop之HDFS架构
上一篇《从零学习Hadoop之认识HDFS》简单介绍了一下HDFS。已经了解到HDFS为Hadoop这个分布式计算框架提供高性能、高可靠、高可扩展的存储服务。HDFS架构是一个典型的主从架构,包括一个NameNode节点(主节点)和多个DataNode(从节点)并提供应用程序访问接口。
NameNode是整个文件系统的管理节点,它负责文件系统名字空间(NameSpace)的管理与维护,同时负责客户端文件操作的控制以及具体存储任务的管理与分配;DataNode提供真实文件数据的存储服务。

机架
Rack是机架的意思,一个Block的三个副本通常会保存到两个或者两个以上的机架中(当然是机架中的服务器),这样做的目的是防灾容错,因为发生一个机架掉电或者一个机架的交换机挂掉了的概率还是很高的。
数据块
Linux系统:磁盘都有默认数据块大小,这是磁盘进行数据读和写的最小单位。文件系统块一般为几千字节,而磁盘块一般为512字节。
HDFS:默认为64MB。
注意:与其它文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间。
为什么HDFS默认的Block为64MB?
HDFS的块之所以这么大,主要是为了把寻道(Seek)时间最小化。如果一个块足够大,从硬盘传输数据的时间将远远大于寻找块的起始位置的时间。这样使HDFS的数据传输速度和硬盘的传输速度更加接近。
块进行抽象带来的好处:
- 一个文件系统的大小可以大于网络中任意一个磁盘的容量。
- 使用块抽象而非整个文件作为存储单元,大大简化了存储子系统的设计。
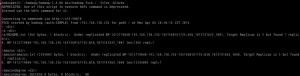
与磁盘文件系统相似,HDFS中的fsck可以显示块信息,例如:
元数据节点
元数据节点NameNode是管理者,一个Hadoop集群这有一个NameNode节点,是一个通常在HDFS实例中的单独机器上运行的软件。
- 管理文件系统名字空间(详细见下)
- 控制外部客户机的访问
NameNode决定是否将文件映射到DataNode的复制块上。
实际的I/O事务并没有经过NameNode,只有表示DataNode和块的文件映射的元数据经过NameNode。
NameNode主要功能:
- NameNode提供名称查询服务,它是一个Jetty服务器。
- NameNode保存metadata信息。
- NameNode的metadata信息在启动后会加载到内存。
块大小为64MB,如果上传文件小于该值,那么仍然会占用一个Block的NameNode metadata,但是物理存储不会占用64MB。
数据节点
数据节点DataNode也是一个通常能够在HDFS实例中的单独机器上运行的软件。DataNode通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop的一个假设四:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode的相应:
- HDFS客户机的读写请求;
- NameNode的创建、删除和复制块的命令。
NameNode依赖来自每个DataNode的定期心跳(heartbeat)消息。每条消息都包含了一个块报告,NameNode可以根据这个报告验证块映射和其它文件系统的元数据。
DataNode的功能:
- 保存Block,每个块对应一个元数据信息文件。
- 启动DataNode线程的时候会向NameNode汇报Block信息。
- 通过向NameNode发送心跳保持与其联系(3秒一次),如果NameNode 10分钟没有收到DataNode的心跳,则认为其已经lost,并将其上的Block复制到其它DataNode上。
辅助元数据节点
- SecondaryNameNode通知NameNode准备提交edits文件,此时主节点产生edits.new。
- SecondaryNameNode通过http get方式获取NameNode的fsimage与edits文件(在SecondaryNameNode的current同级目录下可见到 temp.check-point或者previous-checkpoint目录,这些目录中存储着从namenode拷贝来的镜像文件)。
- SecondaryNameNode开始合并获取的上述两个文件,产生一个新的fsimage文件fsimage.ckpt。
- SecondaryNameNode用http post方式发送fsimage.ckpt至NameNode。
- NameNode将fsimage.ckpt与edits.new文件分别重命名为fsimage与edits,然后更新fstime,整个 checkpoint过程到此结束。
SecondaryNameNode会周期性地将EditLog文件进行合并,合并的前提:
- EditLog文件到达某一阈值时对其进行合并。
- 每隔一段时间对其进行合并。
上述对应配置为:
- fs.checkpoint.size定义了edits日志文件的最大值,一旦超过这个值会导致强制执行检查点(即使没到检查点的最大时间间隔)。默认值是64MB。
- fs.checkpoint.period,指定连续两次检查点的最大时间间隔, 默认值是1小时。
名字空间
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。 文件系统名字空间的层次结构和大多数现有的文件系统 类似:用户可以创建、删除、移动或重命名文件。当前,HDFS不支持用户磁盘配额和访问权限控制,也不支持硬链接和软链接。但是HDFS架构并不妨碍实现 这些特性。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。
数据复制

块备份原理
Block是HDFS文件系统的最小组成单元,它通过一个Long整数被唯一标识。每个Block会有多个备份(默认为3)。存放策略:
- 第一块:在本地机器的HDFS目录小存储一个Block。
- 第二块:不同Rack的某个DataNode上存储一个Block。
- 第三块:在该机器的同一个Rack下的某台机器上存储最后一个Block。
怎么设置集群Block的备份数?
方案一:修改配置文件hdfs-site.xml。
方案二:通过命令更改备份数目。bin目录下运行:hadoop fs -setrep -R 1 /
注:方案一需要重启HDFS,方案二不需要重启HDFS。
机架感知
通常,大型Hadoop集群是以机架的形式来组织的,同一个机架上不同节点间的网络状况比不同机架之间的更为理想。另外,NameNode设法将数据块副本保存在不同的机架上以提高容错性。Hadoop允许集群的管理员通过配置dfs.network.script参数来确定节点所处的机架。当这个脚本配置完毕,每个节点都会运行这个脚本来获取它的机架ID。默认的安装假定所有的节点属于同一个机架。
待续
后面会介绍Hadoop的RPC机制。
挺好的。